


6b.4. Research
Finding what you want on the Web
Finding useful, correct information on on the Web can be more difficult than it seems. Suppose that you are playing a trivia game with a group of friends and want to know about rams, specifically the question is "How long can a ram stay under water?" Try it! Use your favorite search engine and be tenacious. (Who would have thought "ram" could mean so many different things?) Answer below.
For a few lucky (or facile) people, that may not have presented a challenge. Try this one instead. Consider writing a paper for a class that the instructor tells you will be published. The paper refers to the origins of humanity (or mankind). Since everyone who reads it will not share your beliefs, you would like to cite a credible (otherwise, why bother) reference that (at least most) readers will find acceptable. Try it – find that credible reference. Discussion below.For a somewhat more daring and ribald challenge, find how the following terms are related in science: hymen vulva pubes anus labia. Female genitalia is not the correct answer, neither is gynecology, etc. Your looking for something else. Answer below.

Hydraulic water ram
By Jorge Daniel Czajkowski (Propia) [CC-BY-SA-2.5], via Wikimedia Commons

Ram
By Lucy Boynton (Hebridean Sheep) [CC-BY-2.0], via Wikimedia Commons

Ram Truck
public domain image

1GB DDR RAM memory module
public domain image
Using the Internet for Research [src1] [src2]
The Internet is widely used and readily accessible to hundreds of millions of people in many parts of the world. It can provide practically instant information on most topics, and has a profound impact on the way ideas are formed and knowledge is created and shared.
Research is a broad term. In its most general sense, it is any gathering of data or information. This would include aimlessly browsing the Web, reading a (any) magazine, and watching South Park. Your instructor, if your in school, or your boss, will expect more. You should expect more.
Here, the term is used to mean a targeted and systematic attempt to discover facts, information supported by reasonable argument or consensus, reliable data, and even opinion (when recognized as such) in an attempt to further understanding. Inherent in this definition is the identification of a topic, a research plan, and an evaluation of the source(s) of information. This does not preclude research into minority or dissenting views on a topic. Most good research will address multiple ("all" is too strong a word) views.
Common applications of Internet research include personal research on a particular subject (something mentioned on the news, a health problem, etc), students doing research for academic projects and papers, and journalists and other writers researching stories. It should be distinguished from scientific research — research following a defined and rigorous process.
Internet research & Search engines
Compared to the Internet, print-only resources physically limit access to information. A book or journal has to be identified, then actually obtained. On the Internet, the Web can be searched, and typically thousands (or millions) of pages can be found with some relation to the topic, within seconds. (A Google search for the required phrase "cold fusion" and the required keyword "physics" resulted in 22 hits. Nice. Just entering the three keywords: 2.7M hits.) In addition, email, mailing lists, online discussion forums (message boards, blogs), and other personal communication facilities (instant messaging, IRC, newsgroups) can provide direct access to experts and other individuals with relevant interests and knowledge. However, difficulties persist in winnowing out the chaff and verifying expertise, a writer's credentials or credibility, and therefore the pertinence and accuracy of the information obtained.
Additional difficulties in Internet research center around search tool bias and whether the searcher has sufficient skill to draw meaningful results from the abundance of material typically available. The first resources retrieved may not be the most suitable resources to answer a particular question. For example, popularity is often a factor used in structuring Internet search results but the most popular information is not always the most correct or representative of the breadth of knowledge and opinion on a topic. (Aristotle's view of physics – earth, water, air & fire – held sway for thousands of years.)
Although search engines are programmed to rank web sites based on their popularity and relevancy, empirical studies indicate various political, economic, and social biases in the information they provide. These biases could be a direct result of economic and commercial processes (e.g., companies that advertise with a search engine can become more popular in its organic search results), and political processes (e.g., the removal of search results in order to comply with local laws). Google Bombing is one example of an attempt to manipulate search results for political, social or commercial reasons.
At least one major search engine, Google, selects results based on your location. This is a "feature" that you cannot currently turn off. (I recommend setting your location to the country in which you are located.)
Further, since no search engine can claim to index the entire, ever changing Internet, the best resources may not be found by the search engine at all.
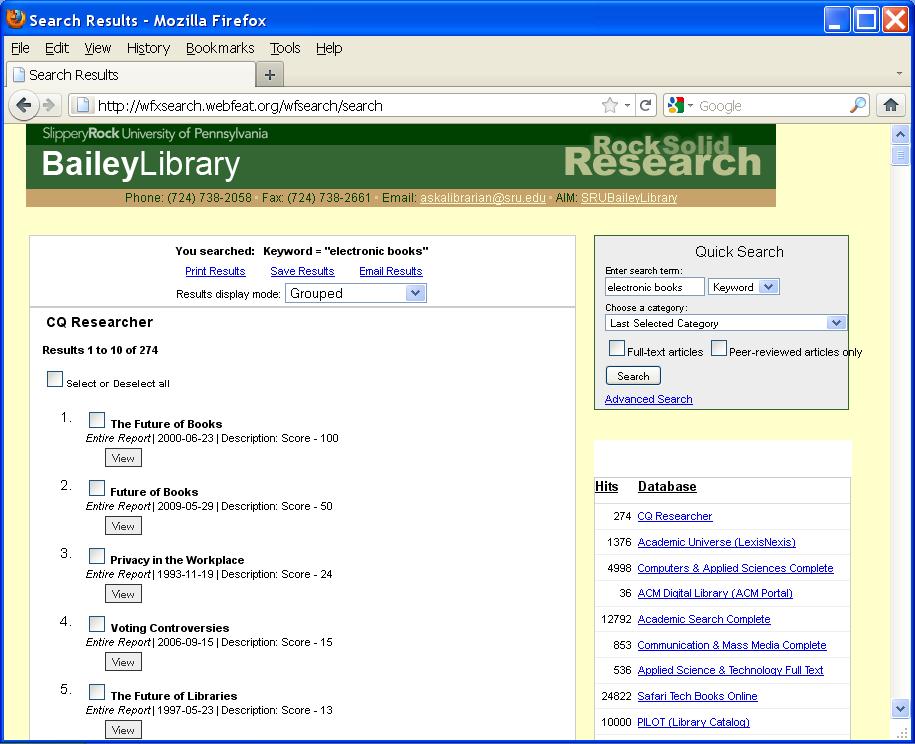
Library Search results page for term "electronic books" – By Paul Mullins: screenshot
Books are harder to find & use?
* Specialized search engines (available on library sites) can easily find relevant articles & books (Bailey Library)
* Bias can be hard to define, but the search tools are generally paid research services rather than supported by ads or click-throughs
* Books and journals can often be read online (check with your library) or purchased and downloaded instantly to an ebook reader
* Over 2,000,000 free ebooks are available as of 2009.
* Despite self publication, most books & journals go through an editorial publication process (though that doesn't guarantee a "good" resource)
* Errata - In paper form, corrections are separate and/or not timely. The easy to update nature of web pages can make them more up to date (but also more trendy and subject to vandalism).
Opinion –
Currently the Web is a hammer, so research looks like a nail.
Search Skills
Basic search queries involve entering a phrase, question, or set of keywords. Search engines prefer results that include all of the the terms provided, near one another, and in the order provided. Generally, they also prefer results with the query words in the document title or keywords, or near the top of the page. And, they prefer results that are "popular". This is often a sufficient strategy for casual searching.
Part of the skill set for performing Internet research with finesse involves using the search modifiers NOT and OR (AND is presumed as part of the basic search engine strategy). Also, requiring a particular word or exact phrase, providing a word stem, dates, etc., can allow you to create better search engine queries. Advanced Internet searching should be available in whatever tool you choose to use. (Look for a link leading to the advanced search page.) Advanced search pages generally offer a form fill-in interface with many options to help focus your search. (Technically, AND, OR & NOT are Boolean operations. For more information on how they work, try this slide show.)
There is also a skill in evolving a search query as we repeatedly make requests of search engines and as we grow more familiar with a topic and how it is organized. Most Internet search engines treat a second query the same as the first. Some search tools allow you to search only your previous results, narrowing down the field of hits, rather than creating a new (perhaps smaller) field of hits.
Some information may require further search skills to retrieve. Much of the information on the Internet is created without regard to how search engines will perceive it. Some is created in formats that are dictated by tradition, technology, or for a particular audience (like these modules, for example). In such case, a familiarity with directories, databases not indexed by search engines, and an attentiveness to types of organization may reveal the key to finding missing information.
Search Tools
Search Engines
A Web search engine uses software known as a web crawler to follow the hyperlinks connecting the pages on the (always changing) World Wide Web. The information on these Web pages is indexed and stored by the search engine. To access this information, a user enters keywords in a search form and the search engine queries its indices to find Web pages that contain the keywords and displays them in a results page (or list of hits). The list typically includes hyperlinks and brief descriptions of the content found. Search results are ranked using complex algorithms, which take into consideration the location and frequency of keywords on a Web page, along with the quality and number of external hyperlinks pointing at the Web page.

US Share of searches, 2008
By Nielsen Online [CC-BY-2.0], via Wikimedia Commons

Diagram of the metasearch concept
By JakobVoss (Own work) [CC-BY-SA-3.0 or GFDL], via Wikimedia Commons
Metasearch Engines
A Metasearch engine enables users to enter a search query once and have it run against multiple search engines simultaneously, creating a list of aggregated search results. Since no single search engine covers the entire web, a metasearch engine can produce a more comprehensive search of the web. Most metasearch engines automatically eliminate duplicate search results and indicate sponsored links. You can find metasearch engines by (no kidding) searching for them. One well known metasearch engine, dogpile, combines results from Google, Yahoo! Search, and Bing, as well as authority sites Kosmix and Fandango.
Web directory
A Web directory organizes subjects in a hierarchical fashion that lets users investigate the breadth of a specific topic and drill down to find relevant links and content. Web directories can be assembled automatically by algorithms or hand crafted. Human-edited Web directories have the distinct advantage of higher quality and reliability, while those produced by algorithms can offer more comprehensive coverage. The scope of Web directories are generally broad, such as the Open Directory Project, Yahoo! and the WWW Virtual Library, covering a wide range of subjects, while others focus on specific topics. A directory may be just a list of links related to a subject, while portals tend to be more general in subject area and more specific in accessing resources of a particular enterprise.
The screenshot to the right shows part of Open Directory links for the topic "Web 2.0", along with the required solicitation for volunteer help with the project.

Open Directory screenshot for
Computer: Internet: WWW: Web 2.0
Licensed under a Creative Commons Attribution 3.0 Unported License. (Ref OD License, Jul 04, 2011)
|
Specialty search tools
Specialty search tools enable users to find information that conventional search engines and metasearch engines cannot access because the content is stored in databases. In fact, the vast majority of information on the web is stored in databases that require users to go to a specific site and access it through a search form. Often, the content is generated dynamically, i.e., the page is created when you ask for it. As a consequence, Web crawlers are unable to index this information. In a sense, this content is "hidden" from search engines, leading to the term invisible or deep Web. Specialty search tools have evolved to provide users with the means to quickly and easily find deep Web content. These specialty tools rely on advanced bot and intelligent agent technologies to search the deep Web and automatically generate specialty Web directories, such as the Virtual Private Library.
Internet Research Software
Internet Research Software enables you to capture information you find while performing Internet research. This information can then be organized in various ways including tagging and creating hierarchical trees. The goal is to collect information relevant to a specific research project in the one place, so that it can be found and accessed again quickly.
These tools typically go beyond just capture and enable content to be edited, notes to be added and information to be cross referenced. Full text search aids in quickly locating information and filters enable you to drill down to see only information relevant to a specific query.

By capturing and keeping information you don't have to worry about web pages and whole sites disappearing or being inaccessible. Internet Research Software greatly enhances Internet research by enabling you to build knowledge and reuse it. Available software includes Surfulater, Evernote, WebResearch Professional and Scrapbook.
The highly recommended sidebar discusses plagiarism.
Searching
Google is, by far, the most used search engine in the US - that doesn't make it the best choice for your search, but it does make it the best choice for examples here. Wikipedia will be discussed for similar reasons. Regardless of the tools you choose, learn to use them well. Google provides an extensive guide to using their search engine.
Step 1: Getting Started
Determine what your topic is and what kind of research you need to do. Is it for personal information/curiosity or for a term paper? How important is it that the results are complete and accurate? If your instructor mentions the relationship of early computing to the military, and you simply want to verify or "fill in the blanks", then jump right into Google or Wikipedia. Otherwise, think before you search.
The best answers to many questions may not call for an Internet search at all. Or, they may require very careful, even complex, searches. For a term paper, consider starting at the library. Most colleges have online research tools. Use them! (At SRU, these tools are accessible from the library's home page.) Talk to a research librarian. Setting up an appointment with an expert on finding information can save you an enormous amount of time.
Specific searches may require other expertise. Most people develop a list (formal or informal) of "trusted" sites and other resources. You just need to make sure you ask a knowledgable person. For a health problem, ask a medical professional where to look. For class assignment, ask the instructor if he/she has any recommendations. (Don't forget that you still have to evaluate the resources yourself.)
Step 2: Planning
Assuming that you have determined the need to perform your own web search, you next need to determine appropriate search terms, tools, and sources. Generic terms are not as good a technical or professional terms. Some search engines are better than others for certain things. (Google actually provides special search tools for many areas, including a customized search.) Consider limiting your search to specific Internet domains (perhaps, educational) or sites (National Institutes of Health – nih.gov).
This is a good time to use Wikipedia. Get an overview of the subject. Determine what you should look for and the proper terms to use. Look at the references for the Wikipedia article — are they useful primary sources?
Step 3: Digging for Answers
Your research plan may call for many interrelated searches. Consider one particular facet or line of inquiry...
Use multiple search engines and dig past the top ten. (If it was always on top of the list, they wouldn't call it research.) Different search engines will garner different results and, in most cases, you don't care what the most "popular" answer is.
Refine your search — my Google search for "ram" returned 952,000,000 hits! Reviewing the top 100 would be a fairly meaningless 0.00001% of what was available. Searching for the phrase "ram cichlid" narrowed this down to 63,300, which is still too large to peruse.
Use the advanced search feature (or special characters) to get rid of the extraneous and focus on the relevant. (Perhaps, the most important is to use an "exact phrase".) In addition, Google provides a large number of specialized search operators.
Although you can (typically) limit your results by language, don't forget that all the world's knowledge isn't written in English. Google provides a translate function that works reasonably well.
Step 4: Look before you click
Remember that anyone can post anything on the web and the majority of it is completely unedited.
Look at the URLs provided for the sites you are considering. What is the top-level domain? A commercial site (.com) isn't necessarily biased, but a primary goal of commerce is to make a profit. An organization (.org) is not necessarily a non-profit. If it is a government site (.gov), we know it has to be trustworthy, right? If you're not familiar with the domain, look it up.
Educational sites (.edu) in the US are primarily accredited colleges and universities, but expertise can be hard to distinguish. Characters like the tilde (~) or percent (%) tend to indicate individual, not institutional pages. (For some sites, the word user or member would indicate the same.) Is the person an expert or a student (or both)? Keep in mind that most colleges thrive on and actively promote the discussion of "alternative views", that is controversy. Blogs? Ask yourself why anyone would care what this person thinks. (Who is the author and what are their credentials?)
If you are not familiar with the hosting organization, work your way backward (right to left) through the URL deleting one file or directory name at time until you reach the domain name. Look for the "home page" for this organization. Does it indicate (a likelihood of) bias?
Step 5: Evaluate your sources
Looking at the URL (step 4) is just a preliminary evaluation to cut down on how much you have to review.
Who owns the domain? Use a "whois" server like Internic to find out, then Google that organization or person.
Does the content reflect bias? Is it satire, a parody, spam? Bias needs to be recognized, but doesn't (in itself) make the information unusable. You don't want to get caught citing satire as a serious resource in your term paper, though.
Many recommend checking for the author of the web page, credentials, "last updated", etc., all nicely organized in professional looking web site. This is a throwback to print media and the (relatively) unchanging Web 1.0. All of these are elements in your analysis of the credibility of the site, but they are all easy to spoof. Many of my students have skipped all the detailed analysis described and simply looked at the page – if it looks good, it must be a good source. When done properly, you are doing the equivalent of looking at a book's copyright page, about the author, looking at the index and table of contents, and flipping through the book looking for professionalism. Improperly, you are simply "judging a book by its cover".
Do you have to study every resource?
Obviously this depends partly on what kind of research you are doing. If you are selecting a brain surgeon, I suggest extensive research. If you are writing a one page essay for a class, you can take a more moderate approach. Also, some resources have well-known credentials, for example, the National Institutes of Health, the New York Times or the Wall Street Journal. (However, note that both of the newspapers are often claimed to be biased.)
The sidebar is a humorous look at what can happen when you don't check check things out.
 identifying reliable sources
identifying reliable sources
 evaluating a web site
evaluating a web site
 Evaluating Internet Research Sources
Evaluating Internet Research Sources
Wikipedia
Many professors will not allow you to cite Wikipedia in a research paper. Why? Well, it can be summed up as – at any given moment a Wikipedia article can be terribly wrong. But don't take my word for it, look at what Wikipedia and it's founder have to say:
- Wikipedia Founder Discourages Academic Use of His Creation
- Academic use of Wikipedia
- Researching with Wikipedia
- Reliability of Wikipedia
Unintended Bias
In the last module, I stated (implicitly) that the most used web browser was Chrome. I linked this to the source, W3schools.com Browser Statistics, a fairly reliable source for web-related information. So, as of November 2016, 73.8% of webizens use Chrome. Really?
Consider the source. This technical web site is counting visitors to their site and those visitors might be considered fairly sophisticated web users. To get a better overall measure we need to look elsewhere. Wikipedia cites several resources and the stats for each. From that, you can get a better picture of actual usage. (Chrome still wins.)
Always consider where your information comes from and what biases might be built in.
Challenge Answers
Did you find the answers easily? If so, maybe I need your help. Or, maybe you need to be more honest with yourself. The first question may involve a bit of misdirection, but the answer is (pretty) clear – you got it or you didn't. The second question though??? Ask yourself if your source would be credible to an atheist, a muslim, a Jew, a christian, a Buddhist and an anthropologist? (And, that list included just a small sample of the world's religions.) If you still think you nailed it, congratulations! The last question is based on an oddity I stumbled across with a "whaaat?".
How long can a ram stay under water?
There was no deep thought involved in picking this particular example, and by that I mean that it is not special. Actually, it is fairly mundane.
Depending on the words you search for, common search engines will provide little help. Here Wikipedia wins out, assuming you carefully read the disambiguation page. Use Wikipedia as a starting point for your real research.
Answer: their entire life (a ram cichlid is a kind of fish), or more precisely, 2-4 years.
Origins of mankind
No deep thought necessary here either. Just pick any controversial topic.
In this case, you should have found plenty of sites supporting your view, whatever it is. The problem is finding a resource acceptable to those whose views differ from your own. (A convincing resource would be great, but for controversial topics you may have to settle for acceptable or reasonable.) Assuming the point of the paper isn't to take a stand on this particular issue, this might be a good place to use a phrase like, "some believe", "there is some evidence", "scientists believe", or "most theists believe".
hymen vulva pubes anus labia
The problem here is that there is so much information available on what appears to clearly be the subject of the query. What you should have done is rule out terms like genitalia (-genitalia -gynecology). It's still a challenge. Knowing just a little more makes it easy. Add any one of the following keywords to find the result almost immediately: taxonomy, bivalve, or clam. In a taxonomy of molluscs, the famous Carolus Linnaeus, apparently got a little carried away.
