


6a.3. World Wide Web [src]
The World Wide Web (abbreviated as WWW or W3 and commonly known as the Web), is a system of interlinked hypertext documents accessed via the Internet. With a web browser, one can view web pages that may contain text, images, videos, and other multimedia, as well as navigate between them via hyperlinks. Using concepts from earlier hypertext systems, British engineer and computer scientist Sir Tim Berners-Lee, now living in Lexington, MA as the Director of the World Wide Web Consortium, wrote a proposal in March 1989 for what would eventually become the World Wide Web. At CERN in Geneva, Switzerland, Berners-Lee and Belgian computer scientist Robert Cailliau proposed in 1990 to use "HyperText ... to link and access information of various kinds as a web of nodes in which the user can browse at will".
How it works
The terms "Internet" and "World Wide Web" are often used interchangeably in every-day speech. However, the Internet and the World Wide Web are not one and the same. The Internet is a global system of interconnected computer networks. In contrast, the Web is one of the services that runs on the Internet. It is a collection of interconnected documents and other resources, linked by hyperlinks and URLs. In short, the Web is an application running on the Internet.


Tim Berners-Lee speaking at the Home Office in Westminster, London.
By Paul Clarke (originally posted to Flickr as Tim Berners-Lee) [CC-BY-2.0], via Wikimedia Commons
Balloon by Paul Mullins: constructed
Viewing a web page on the World Wide Web normally begins either by typing the URL of the page into a web browser, or by following a hyperlink to that page or resource. The web browser then initiates a series of communication messages, behind the scenes, in order to fetch and display it. As an example, consider the Wikipedia page for an article with the URL: http://en.wikipedia.org/wiki/World_Wide_Web
First, the browser resolves the server-name portion of the URL (en.wikipedia.org) into an Internet Protocol address using the global, distributed Internet database known as the Domain Name System (DNS); this lookup returns an IP address such as 208.80.152.2. The browser then requests the desired web page by sending an HyperText Transfer Protocol (HTTP) request across the Internet to the computer at that particular address. It makes the request using the Internet Protocol Suite (TCP/IP). The content of the HTTP request can be as simple as the two lines of text:
GET /wiki/World_Wide_Web HTTP/1.1 Host: en.wikipedia.org
The computer receiving the HTTP request delivers it to Web server software listening for requests. If the web server can fulfill the request it sends an HTTP response back to the browser indicating success, which can be as simple as:
HTTP/1.0 200 OK Content-Type: text/html; charset=UTF-8
followed by the content of the requested page.
The HyperText Markup Language (HTML) – that describes how to display the text – for a basic web page looks like:

IP Address Components
public domain image
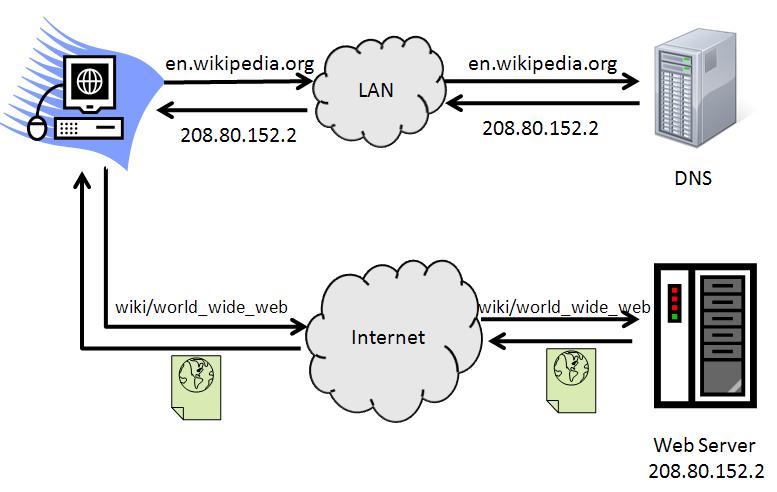
DNS Lookup for web page
By Paul Mullins: constructed
<html> <head> <title>World Wide Web - Wikipedia, the free encyclopedia</title> </head> <body> <p>The <b>World Wide Web</b>, abbreviated as <b>WWW</b> and commonly known the <b>Web</b>), is...</p> </body> </html>
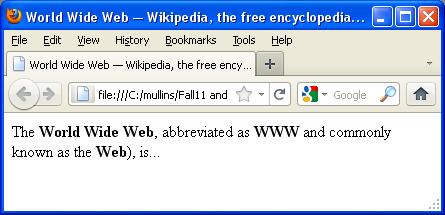
The web browser breaks down the HTML into components, interpreting the markup (<title>, <b> for bold, and such) that surrounds the words in order to draw that text on the screen. (WYSIWYG editors for HTML are available, but they just hide the HTML, they don't replace it.)
Many web pages consist of more elaborate HTML which references the URLs of other resources such as images, other embedded media, scripts that affect page behavior, and cascading style sheets that affect page layout. A browser that handles complex HTML will make additional HTTP requests to the web server for these other Internet media types that are part of the page. As it receives their content from the web server, the browser progressively renders the page onto the screen as specified by its HTML and these additional resources. Often this occurs so quickly that it appears to happen all at once.
Like a basic email message, a web page contains just text, in HTML format.
HTML allows us to include images and more.
When the browser encounters the image tag, it then requests the (binary) image from the server to display on the page at the location specified.
Linking
Most web pages contain hyperlinks to other related pages and perhaps to downloadable files, source documents, definitions and other web resources. These resources are not displayed, rather a link to them is displayed. (This module is full of hyperlinks.) In the underlying HTML, a hyperlink looks like
<a href="http://www.sru.edu">University home page</a>
Such a collection of useful, related resources, interconnected via hypertext links is dubbed a web of information. Publication on the Internet created what Tim Berners-Lee first called the WorldWideWeb (in its original CamelCase, which was subsequently discarded) in November 1990.
The hyperlink structure of the WWW is described by the webgraph shown to the right: the nodes of the webgraph correspond to the web pages (or URLs) the directed edges between them to the hyperlinks.

Web of Information
Uploaded by Chris 73. Licensed under Creative Commons Attribution-Share Alike 3.0 Unported
Over time, many web resources pointed to by hyperlinks disappear, relocate, or are replaced with different content. This makes hyperlinks obsolete, a phenomenon referred to in some circles as link rot and the hyperlinks affected by it are often called dead or broken links. The ever-changing nature of the Web has prompted many efforts to archive web sites. The Internet Archive, active since 1996, is one of the best-known efforts.

Can the basic idea for the web predate computers?
Now that we have talked about the basics of the web, I invite you to look at a longer history — linked, of course.
Using the Web
portal [src]
A web portal or links page is a web site that functions as a point of access to information on the World Wide Web. A portal presents information from diverse sources in a unified way.
Apart from the standard search engine feature, web portals offer other services such as e-mail, news, stock prices, information, databases and entertainment. Portals provide a way for enterprises to provide a consistent look and feel with access control and procedures for multiple applications and databases, which otherwise would have been different entities altogether.

Sample web portal
By foudyl zaouia (Own work) [GFDL or CC-BY-SA-3.0-2.5-2.0-1.0], via Wikimedia Commons
Examples of public web portals are AOL, Excite, MSN, Netvibes, and Yahoo!.
An enterprise portal is a framework for integrating information, people and processes across organizational boundaries. It provides a secure unified access point, often in the form of a web-based user interface, and is designed to aggregate and personalize information through application-specific portlets. One hallmark of enterprise portals is the decentralized content contribution and content management, which keeps the information always updated. An enterprise portal is a corporate version of the more general intranet portal.[src]
Slippery Rock Univerity's web portal is mySRU.sru.edu. Note how it differs from the SRU home web page/site (www.sru.edu).

SRU "enterprise" portal
By Paul Mullins: screenshot
search engines [src]
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results and are often called hits. The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained by human editors, search engines operate algorithmically or are a mixture of algorithmic and human input.
A search engine is a class of programs that helps to find information by specific keywords, questions, pictures, and sounds (in various languages). It works by sending special programs, called spiders (or crawlers, bots, robots, agents), to look through the World Wide Web, following links from one web page to another and indexing the words on that site. It helps minimize the time searching for information and increase the amount and quality of it, based upon what you are (presumed to be) interested in.
The specific algorithms used by various search engines are proprietary. We will consider effective searching for information later in the next module.
The Wikipedia article on search engines lists those that are currently available (active). You should familiarize yourself with several.

OpenWebSpider
By Stefano Alimonti (http://www.openwebspider.org/) [GFDL or CC-BY-SA-3.0], via Wikimedia Commons
Web 1.0
As originally designed, and as it existed through most of the 90's, web pages were static. That is, the web pages changed only when someone manually edited the page. During the late 90's more and more pages were becoming dynamic and interactive. The user did not always have to specifically request information (usually by clicking), rather information was sometimes requested automatically or "pushed" to the user's page. As a result, the Web became more interactive and "social". The term Web 2.0 was coined in recognition of a major change in how the Web was being used and how it had developed. Web 1.0 is, of course, what came before.
Web 2.0 [src]
Web 2.0 web sites allow users to do more than just retrieve information. By increasing what was already possible in "Web 1.0", they provide the user with more user-interface, software and storage facilities, all through their browser. This has been called network as platform computing. Users can provide the data that is on a Web 2.0 site and exercise some control over that data. These sites may have an "architecture of participation" that encourages users to add value to the application as they use it. (A fancy way of saying that Facebook would be boring indeed if no one posted anything.)
The Web 2.0 offers all users the freedom to contribute. While this opens the possibility for rational debate and collaboration, it also opens the possibility for "spamming" and "trolling" by less rational users. (In 2016, "fake news" became a much talked about issue also.)
The characteristics of Web 2.0 are: rich user experience, user participation, dynamic content, metadata, web standards and scalability. Further characteristics, such as openness, freedom and collective intelligence by way of user participation, can also be viewed as essential attributes of Web 2.0.

A tag cloud (a typical Web 2.0 phenomenon in itself) presenting Web 2.0 themes
By Original by Markus AngermeierVectorised and linked version by Luca Cremonini [CC-BY-SA-2.5], via Wikimedia Commons
How it works
The client-side, web browser technologies used in Web 2.0 development allow the browser to upload and download new data from the web server without undergoing a full page reload. Using these techniques, Web designers can make their pages function like desktop applications. For example, Google Docs uses this technique to create a Web based word processor.
On the server side, Web 2.0 uses many of the same technologies as Web 1.0. New scripting (programming) languages are used by developers to dynamically output data using information from files and databases.
.jpg)
Web Trends (2007) - Who the players are
By Otto Nassar from Bogot�, Colombia (WebTrends 2007 / otro mapa de web 2.0) [CC-BY-SA-2.0], via Wikimedia Commons
What has begun to change in Web 2.0 is the way this data is formatted. In the early days of the Internet, there was little need for different web sites to communicate with each other and share data. In the new "participatory web", however, sharing data between sites has become an essential capability. To share its data with other sites, a web site must be able to generate output in machine-readable formats such as XML. When a site's data is available in one of these formats, another web site can use it to integrate a portion of that site's functionality into itself, linking the two together. When this design pattern is implemented, it ultimately leads to data that is both easier to find and more thoroughly categorized, a hallmark of the philosophy behind the Web 2.0 movement.
Web Browsers [src]
A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier (pointed to by a URL) and may be a web page, image, video, or other piece of content. Hyperlinks present in resources enable users to easily navigate their browsers to related resources.
Although browsers are primarily intended to access the World Wide Web, they can also be used to access information provided by web servers in private networks or files in file systems.
Usage statistics show the major web browsers, in order of use, are Google Chrome, Firefox, Internet Explorer, Apple Safari, and Opera. All but Internet Explorer are available for free. Wikipedia describes many more (see list). Rockmelt is a social web browser integrating Facebook and Twitter in the application — purchased by Yahoo, Rockmelt was discontiued almost immediately with functionality being added to Yahoo.

Firefox, the second-most widely used web browser
By Own work (Wikipedia) [GPL or LGPL], via Wikimedia Commons
 #169 Which Browser is for you?
#169 Which Browser is for you?
